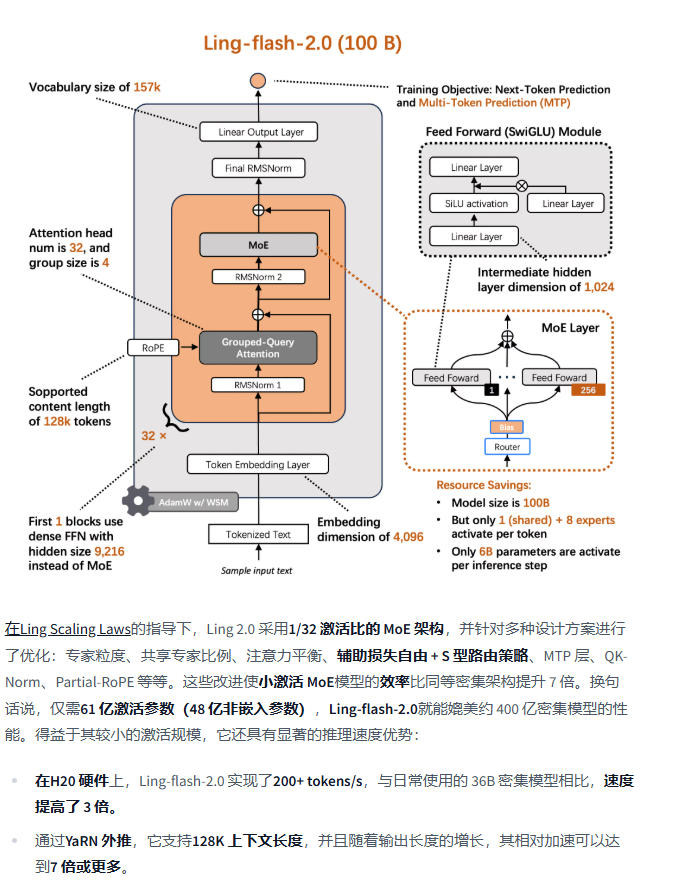
现在大家都习惯了“大模型=大参数”的逻辑,似乎参数越多就意味着能力越强。可是真实落地的时候,大模型往往训练成本高、推理延迟大,还吃掉大量显存,效率问题越来越突出。今天蚂蚁百灵大模型团队正式开源了 Ling-flash-2.0 ——它用 100B 总参数、仅 6.1B 激活(非 embedding 激活 4.8B) 的轻量配置,在多个权威榜单上打出了媲美甚至超越 40B Dense 模型的成绩。
这不是一次简单的模型迭代,而是给整个 MoE(Mixture of Experts)架构找到了一个新答案。推理速度、任务性能、部署成本,三者之间终于出现了新的平衡点。下面我们就一起来看看 Ling-flash-2.0 的特别之处,以及怎么在本地或云端免费体验。

一、Ling-flash-2.0 模型介绍
Ling-flash-2.0 是 Ling 2.0 系列的第三款模型,核心亮点就是 以小博大:
- 1/32 激活比例:每次推理只激活 6.1B 参数,大幅降低计算量。
- 共享专家机制:通用知识模块被复用,避免冗余计算。
- Sigmoid 路由 + 无 Aux Loss:保证专家均衡激活,训练更稳定。
- MTP 层、QK-Norm、Half-RoPE:在训练目标、注意力机制、位置编码等方面做了极致优化。
最终结果是:6.1B 激活参数≈40B Dense 模型性能,推理速度快了 3 倍以上,在 H20 平台上达到 200+ tokens/s。输出越长,加速优势越明显。
二、功能亮点
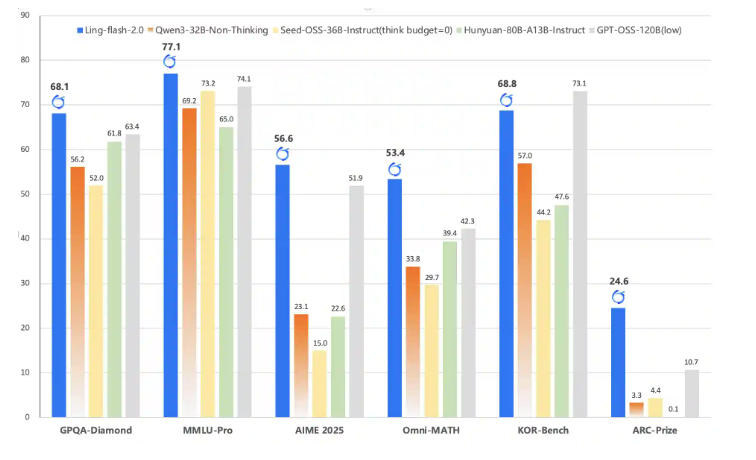
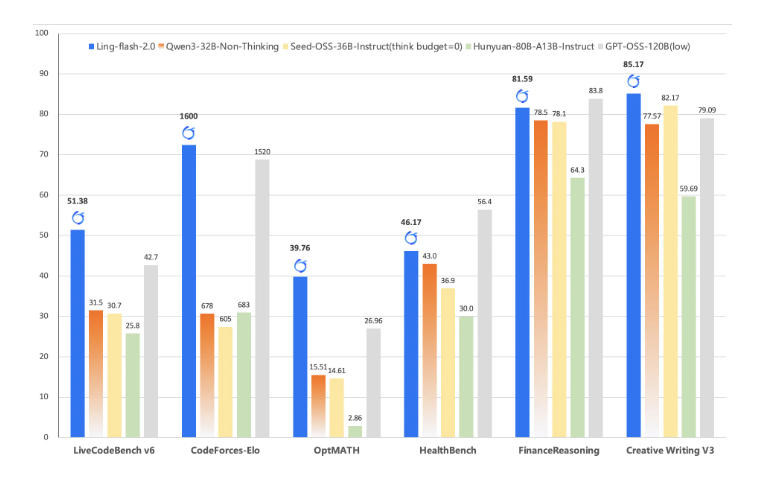
- 高难推理:在 AIME 2025、Omni-MATH 等数学竞赛级任务上表现突出,多步推理稳定。
- 代码生成:在 LiveCodeBench、CodeForces 等评测中优于 Qwen3-32B、GPT-OSS-120B 等模型,能自动 debug、优化风格。
- 前端研发:与 WeaveFox 团队联合训练,引入视觉增强奖励(VAR),UI 生成既美观又实用。
- 长文本支持:原生 32K 上下文,通过 YaRN 扩展到 128K tokens,适合文档、代码库处理。
- 多语言能力:词表扩展到 156K,覆盖 30+ 语种,多语言理解和生成更稳定。
官方对于此次模型的亮点描述:

三、安装与使用教程
1. 本地环境准备
- 推荐 Python 3.8+,并安装依赖:
pip install transformers accelerate safetensors
- 确保有一张 24GB+ 显存 GPU,更理想是 A100 80GB 或多卡并行。
2. Hugging Face 使用示例
from transformers import AutoModelForCausalLM, AutoTokenizer
model = "inclusionAI/Ling-flash-2.0"
tokenizer = AutoTokenizer.from_pretrained(model)
model = AutoModelForCausalLM.from_pretrained(
model, device_map="auto", trust_remote_code=True
)
messages = [
{"role": "system", "content": "You are Ling, a helpful assistant."},
{"role": "user", "content": "写一个Python函数,计算斐波那契数列第n项"}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
3. vLLM 部署 API
git clone -b v0.10.0 https://github.com/vllm-project/vllm.git
cd vllm
wget https://raw.githubusercontent.com/inclusionAI/Ling-V2/main/inference/vllm/bailing_moe_v2.patch
git apply bailing_moe_v2.patch
pip install -e .
启动本地服务:
vllm serve inclusionAI/Ling-flash-2.0 --max-model-len 131072
调用方式:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "Ling-flash-2.0", "messages": [{"role": "user","content":"你好"}]}'
四、硬件需求与使用建议
- 推荐配置:2×A100 80GB 或 4×RTX 4090。
- 消费级显卡:单卡 24GB 也能跑,但需 INT4 量化,速度会下降。
- 云端替代:可在 ModelScope 或 SiliconFlow 免费试用,不受硬件限制。
五、Ling-flash-2.0 对比主流模型
| 模型 | 架构 | 激活参数 | 上下文长度 | 推理速度 | 适用场景 |
|---|---|---|---|---|---|
| Ling-flash-2.0 | MoE (1/32 激活) | 6.1B | 128K | 200+ t/s | 数学推理、代码、前端 |
| Qwen3-32B | Dense | 32B | 32K | 中等 | 中文任务、多轮对话 |
| DeepSeek-V3 | MoE | 数百B | 128K+ | 慢 | 超大规模科研 |
| GPT-4 | 未公开 | 数万B+ | 128K | 慢 | 通用问答、写作 |
| Yi-34B | Dense | 34B | 32K | 慢 | 中文问答、创意写作 |
Ling-flash-2.0 的优势在于 性能/成本比:只需 6B 激活参数,就能打平甚至超越 40B Dense 模型。
六、资源链接合集
| 资源类型 | 链接 |
|---|---|
| GitHub 源码 | inclusionAI/Ling-V2 |
| Hugging Face 模型卡 | Ling-flash-2.0 |
| Hugging Face Base 模型 | Ling-flash-base-2.0 |
| ModelScope 模型 | Ling-flash-2.0 |
| 技术论文 | Scaling Laws for Efficient MoE LLMs |
| 官方报道 | 机器之心 – 蚂蚁开源 MoE 模型 |
小编总结
Ling-flash-2.0 的意义,不只是“参数小”,而是告诉大家:模型智能不止于规模,更在于架构与训练策略。它用 6.1B 激活参数跑出了 40B Dense 的表现,让开发者在更低成本下享受更强大 AI 助手。
未来如果你想要体验高效 MoE 模型,可以直接去 Hugging Face 或 ModelScope 下载,或者在云端 API 里用起来。高效大模型的时代,已经来了。 🚀

