Moonshot AI最近推出的 Kimi K2 模型,凭借着惊人的 1T 总参数规模、领先的 MoE 架构设计 和 超强长文本理解能力迅速走红 AI 圈。也是7月份以来,最具代表性的开源万亿级语言模型之一,本期为大家详细分析一下这次Kimi K2有哪些技术优势,并附上api免费调用地址,一起往下看吧。

一、Kimi K2 是什么?
Kimi K2 是由中国初创团队 Moonshot AI 推出的最新万亿级开源大语言模型,采用稀疏激活的 Mixture-of-Experts(MoE)架构,每次推理仅激活 320B 参数,支持超长上下文(最高 128K tokens),专注提升长文本理解、数学推理、代码生成等核心能力。凭借领先的技术结构与出色的实际表现,它正在成为开源大模型阵营中最值得关注的一员。
二、本次Kimi K2 的最大亮点之一是它的参数结构
- 总参数量为 1T(1 万亿)
- 激活参数为 320B(每次推理只调用 320 亿参数)
这正是典型的 MoE(Mixture-of-Experts)架构设计。传统 Transformer 模型是“密集架构”(Dense),每层都会激活所有权重,计算成本与参数量线性相关。而 MoE 模型则是“稀疏架构”,每层拥有多个“专家子网络”,只激活其中少数(如 top-2、top-4、top-8)参与前向传播。
Kimi K2 的具体结构为:
- 每层包含多个专家(experts)
- 采用 top-8 routing 策略:每层选择最相关的 8 个专家进行推理
- 门控机制(Gating Network)控制哪些专家被激活,且支持动态调整
这种设计有几个关键优势:
| 优势 | 说明 |
|---|---|
| 大模型可扩展性 | 可以在不显著增加推理成本的前提下不断扩展总参数量 |
| 任务专精化学习 | 每个专家可学习不同的语义特征,例如某些专家专注数学,另一些擅长代码 |
| 降低计算成本 | 推理时仅激活部分参数,使得实际 GPU 资源消耗远小于全量参数模型 |
📌 值得一提:为了防止 MoE 训练中的梯度不稳定问题,Moonshot 团队使用了名为 MuonClip 的新型优化器,引入 QK-clip(对 attention 中 query/key 做裁剪)来抑制注意力分数爆炸,从而实现 万亿参数级别的稳定训练。
三、为何 Kimi K2 在长文本和复杂任务上表现突出?
Kimi K2 不只是参数大,它在多个关键任务中的表现也非常抢眼,尤其在长文本理解、数学与代码推理和多轮生成控制方面,具备结构性优势。
1. 超长文本处理(128K tokens)
- Kimi K2 支持128K tokens 上下文窗口(远大于 GPT-3.5 的 4K、GPT-4 的 32K/128K)
- Moonshot 明确提出:可以一次性读完一本 20 万字的小说并进行总结分析
这项能力来自以下几点:
- 自研位置编码机制(Position Embedding),可能采用 Rotary Embedding 或 Linear Attention 优化长距离依赖建模
- 层数与宽度配合得当,降低深层 attention 的梯度消散问题
- 优化 attention head 数量,提升长距离 token 之间的联动性
实测场景下,Kimi 可连续理解几十页 PDF 内容,并提供结构化总结,非常适合科研、商业分析等任务。
2. 知识存储与逻辑推理
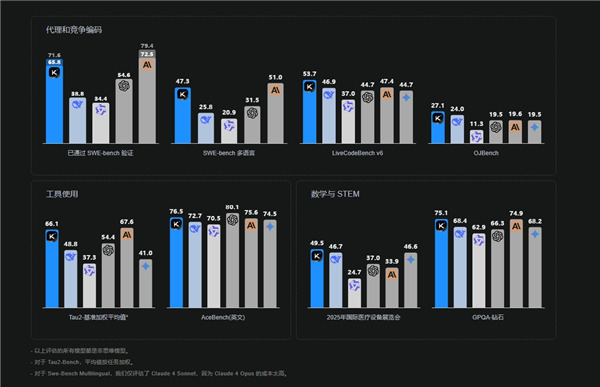
- Kimi K2 在 MATH-500 上得分 97.4%,远超 GPT-4.1 的 92.4%
- 在 LiveCodeBench v6 上,代码准确率达 53.7%,领先 GPT-4.1(44.7%)和 Claude(47.4%)
这类高阶任务对模型提出两个基本要求:
- 海量知识存储:Kimi K2 预训练语料覆盖了 15.5 万亿 tokens,几乎遍及整个互联网公开数据(数倍于 GPT-3 的训练数据)
- 深度链式推理能力(Chain-of-Thought):模型能自动将复杂问题拆分为多步小问题,再组合输出答案
此外,Kimi K2 的 Agent 能力亦表现优秀,具备一定工具调用能力(如查资料、代数推导),为实现自主任务执行(AutoGPT/Function Calling)提供基础。
3. 风格控制与生成质量
- 微调阶段注重对指令跟随(Instruction Following)与输出风格微调
- 可根据用户意图改变语气、风格,如将学术摘要改写为社交文案,或模仿特定品牌调性生成广告内容
- 凭借 MoE 架构和大语料学习能力,生成文本不再“千篇一律”,更具自然感和创意性
四、Kimi K2 与竞品参数与能力对比
| 模型名称 | 总参数量 | 架构类型 | 上下文长度 | 是否开源 | 技术亮点 |
|---|---|---|---|---|---|
| Kimi K2 | 1T(稀疏,MoE) | MoE + Gating | 128K | ✅ 是 | 稀疏激活、超长文本、开源部署、强推理能力 |
| GPT-4 | 未公开(估约1T) | 多模态混合? | 32K-128K | ❌ 否 | 多模态支持、安全性高、闭源 API 商业模型 |
| Claude 3 | 未公开 | Dense | 最长 200K | ❌ 否 | 宪法 AI、指令控制强、逻辑和上下文压缩能力强 |
| Gemini 1.5 | 估为 1.6T+ | MoE + 多模态 | 128K-1M+ | ❌ 否 | 搜索增强能力、多模态(图+文+代码+音) |
✅ 小结:Kimi K2 是目前唯一公开发布并支持128K上下文的万亿参数开源模型,在代码与数学任务上性能已匹敌 GPT-4。
五、Kimi 的网页版、App 与免费 API 接入方式
🧭 想要体验 Kimi K2 强大的对话与生成能力?Moonshot AI 提供了完整的用户产品矩阵,无论是普通用户还是开发者都能轻松上手:
✅ 使用入口一览
| 方式 | 地址或说明 |
|---|---|
| 🌐 网页版 | https://kimi.com —— 直接访问网页,开始智能对话 |
| 📱 移动端 App | 在 App Store / Google Play 搜索“Kimi 智能助手”,下载安装即可使用 |
| 🧪 免费 API | 通过 OpenRouter 平台调用,地址为:https://openrouter.ai/moonshotai/kimi-k2:free |
这个 OpenRouter 提供的免费 API 支持开发者直接使用 Kimi K2 模型进行对话、生成任务,非常适合个人测试和低成本开发项目。
🛠 功能亮点:
- 上传多个文档(PDF、Word、PPT),一次性对话分析
- 上下文窗口支持 128K tokens,可处理长达 20 万字的文本
- 联网搜索能力,可实时查找最新内容并进行整合回答
- 指令控制和风格改写,适用于写作、营销、翻译等多场景
- 代码支持强,涵盖主流语言的生成、优化与调试
不同于 GPT-4 的闭源订阅体验,Kimi 提供开放的使用方式 + 高级推理模型,既适合普通用户,也适合技术开发者。
✅ 总结:Kimi K2 是谁的理想选择?
- 科研人员/分析师:处理海量文档、论文阅读、生成报告
- 工程师/开发者:代码生成、错误定位、多语言开发辅助
- AI 爱好者:探索 MoE 架构、长上下文推理实验、模型部署
Kimi K2 不仅仅是一款参数巨大的语言模型,它代表了 开源 MoE 体系走向成熟 的一次突破,也是中文 AI 生态在全球模型领域中的一次有力发声。


